How to Optimize Continuous Delivery with Continuous Reliability
How to Optimize Continuous Delivery with Continuous Reliability

Continuous delivery is basically a process where code changes are automatically built, tested, and prepared for release to production. In other words, we can say it is a process where you build software in such a way that it can be released to production at any time.

Ref the above diagram, over here what happens when any developers make changes in source code or any developer commits to change in source code repository which can be git repository or a subversion repository will pull that and it will prepare a build.
In the build, it includes Compile, Code Review, Unit Test, Integration Test, and packaging the application in an executable file probably a war file
Read More: Why usability teasing is important in the design process?
After that we can take this build application and deploy on to the test servers for the User Acceptance Test, we can call it UAT as well.
This entire process when it happens automatically it termed as Continuous Delivery But here we are not deploying our application to production automatically we are doing it manually.
Optimization of continuous delivery
There are few points we need to follow for optimization of continuous delivery.
- Slow Commit Stage
- Slow Acceptance Stage
- Failling Tests
- Intermittent Tests
- Pipeline Changes
Deployment Pipeline Diagram:

- Slow Commit Stage:
In the commit stage there are 4 main steps.
- Compile
- Unit Testing
- Analysis
- Build Installers
-
- In this state we must slow down our compilation of code then we give more time to unit testing.
- Unit testing reduces our efforts like if any defects found in Integration testing, then we have to give more time to fix this issue. We must follow all the process for fixing this defect.
- If we do unit testing before integration testing then we can solve these issues before making build.
- We have to do some statistical analysis of some kind then we are going to build some installers.
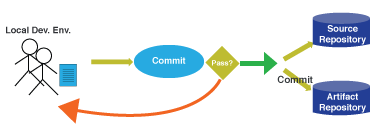
- After commit stage we must go to nest stage like Source Repository or Artifact Repository only if Commit is Pass by the developers. If it is failed don’t go to next stage
Slow Commit Stage – Summary
- Performance of Commit Stage matters
- Teams with a fast Commit Stage keep the build green
- Commit Stage performance as an Important thing. Invest in it!
-
Slow Acceptance Stage:
In the Acceptance Stage there are 4 mail steps.
- Configure Environment
- Deploy Release Candidate
- Smoke Test/Health Check
- Acceptance Test
Configure Environment:
- Here we have to configure our environment based on the requirement. We have to take time and decide which and what type of environment is required the product.
Deploy:
- Successful deployment ends with a Running and Working system.
- So for efficiency we need to consider:
- Time to deploy:
- Keep deployment articact lean
- Packaging strategy make a big difference
- Think about network/infrastructure constraints at deployment time
- Minimize data-sets, where you can
- consider better modularization – Independently deployable services
- Time to migrate data
- Time to start the system:
- Minimise Star-up dependencies & ordering
- Invest in optimizing the code executed during startup – Make it efficient!
- Consider better modularization – Independently deployable services
- Time to validate the system
Acceptance Test:
- There is common cycle:
- Teams start writing acceptance tests and run them all sequentially.
- As number of acceptance tests increases the time, they take to deliver feedback lengthens
- As number of acceptance tests increases the time, they take to deliver feedback lengthens
- Teams parallelize Acceptance Test tactically – Typically teams start by running half the tests on one machine and half on another.
- Teams move to more strategic (automated) parallelization strategy.
- Treat Acceptance Test Isolation Seriously from Day One.
-
Failing Tests:
- The Efficiency of Feedback Cycle is central to the ability of team to keep the test green!
- Continuous Delivery is about: Keeping the build in a releasable state.
- This means we have to give Priorities to Fixing Failing Tests.
-
Intermittent Tests
- Some CI systems even support running failing tests several times!! WHY?
- If the test passes once and fails once, how do you know which result is correct?
- Don’t live with the Intermittent Test- Solve the problem Seriously.
- Treat Intermittent Test as a Failing tests
- Some Common Causes for Intermittent Tests:
- Race Condition
- Poor Test Isolation
- Poorly Designed Test Cases
- Sometimes it is something serious!
- Some CI systems even support running failing tests several times!! WHY?
- Pipeline Changes:
- The deployment pipeline is a Strategic Resource
- Consider SLA for your pipeline
- Redundancy, Clustering, HLA?
- The pipeline is a complex system.
- Consider writing test cases for some pipeline behaviors.
- Consider Blue/Green deployment strategies for pipeline changes
- Use an “Infrastructure as code” approach for all pipeline hosts
Download free guide and learn how automation testing changing the world of software development!